
Integrating DANS metadata in the EHRI-Portal | Select, Match and Go
By René van Horik, DANS
The EHRI-Portal is a web application that holds data from different sources. It offers access to information on Holocaust-related archival material held in institutions across Europe and beyond. DANS, the Dutch national centre of expertise and repository for research data, is one of these institutions.
This blog describes how metadata provided by DANS was integrated into the EHRI-Portal. The intention was to create a fully automated “pipeline” between the DANS data catalogue and the EHRI-Portal. Was this even possible?
Three steps
In general terms a data integration process consists of three steps. First, records have to be selected that are suitable for integration in the Portal. Second, the exchange-format between source (local catalogue) and destination (the Portal) has to be fixed, and, third, the data exchange protocol has to be agreed upon.
The DANS data archive contains metadata on a wide range of scientific disciplines. “Holocaust” is not a specific keyword or topic connected to the records curated by DANS. This meant that a broad search query was created to select every possible record that was relevant for the EHRI-Portal. This set of selected metadata records was evaluated manually. (The search terms used to select potential relevant records were Dutch: ““Holocaust”, “Jodenvervolging”, “Kamp Vught”, “Kamp Amersfoort”, “Kamp Westerbork”, “Concentratiekamp”, “Jodenvervolging”, “Joodse raad”.) In this way the relevance of the records selected have an optimal “precision” and “recall” qualification. About 40% of the records found by using the search terms were not suitable to be integrated in the EHRI-Portal. E.g, not all datasets created by an organisation on “Holocaust and Genocide Studies” is relevant for the EHRI-Portal.
Mapping
The metadata of the DANS catalogue is formatted in the Dublin Core (DC) format, whereas the EHRI-Portal uses the Encoded Archival Description (EAD). This meant that a “mapping” between the two formats had to be created. The mapping of the description fields between the two formats was a one-off action. The mapping protocol fits all records. A complicating factor, however, was the fact that EAD has a hierarchical structure: An archival description belongs to a collection and a collection is part of an institute. The “collection” level had to be created by grouping records, e.g. by creating an “oral history” collection and a “second world war” collection. This grouping process could be automated based on similar terms in the keyword section of the Dublin Core records.
Harvesting
For the exchange of the metadata records the OAI-PMH protocol was used. The DANS data archive supports this protocol. Based on a unique identifier that is part of the metadata a OAI-PMH verb can be compiled that creates a machine-readable record in XML format. This record is harvested by the EHRI-Portal and integrated into the Portal database.

Human intervention
To conclude, human intervention remains necessary in the process to integrate the distributed metadata of the DANS data catalogue in the EHRI-Portal. The idea is to query the DANS collection each year with the broad search terms and manually remove records that are not relevant. The query has a timestamp, so the integration process will not take records into consideration that are already part of the EHRI-Portal. Each new record can be harvested by using the OAI-PMH protocol and based on rules the mapping between the metadata formats will be done to make the data suitable for the EHRI-Portal.
To find out more about integrating data into the EHRI Portal visit the EHRI for Institutions webpage.
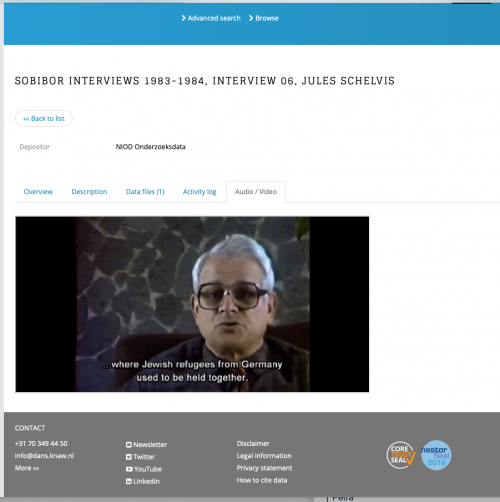
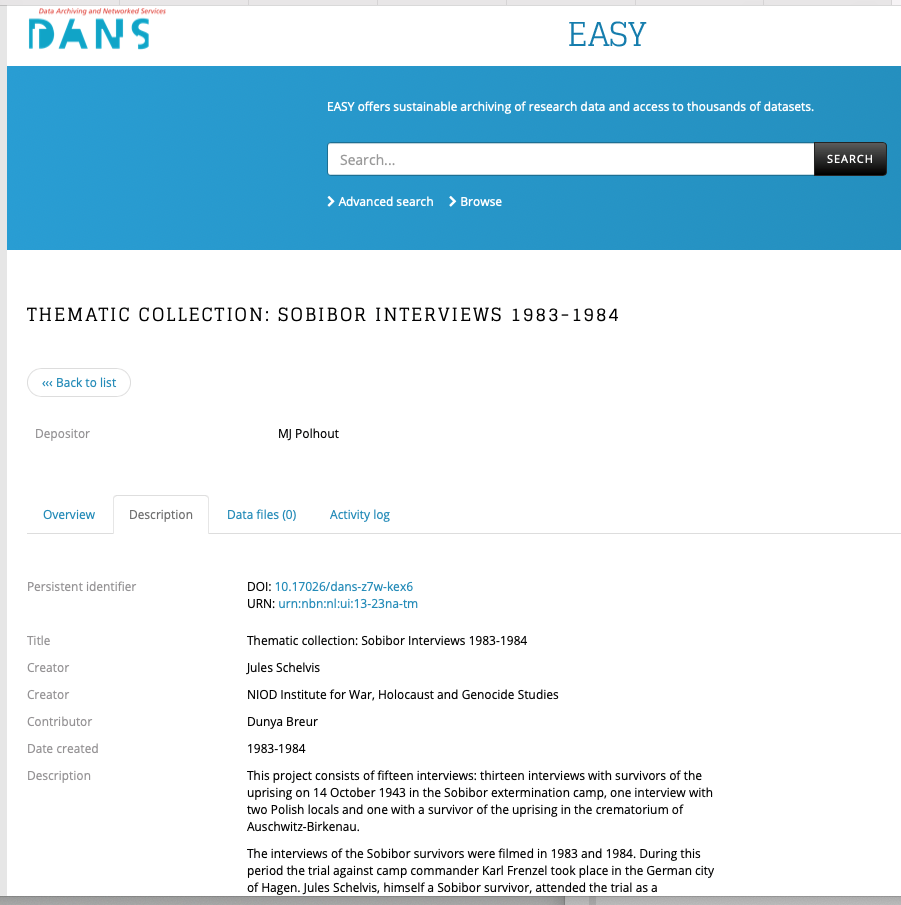
Image at the top: An interview that is part of the collection from the example, https://easy.dans.knaw.nl/ui/datasets/id/easy-dataset:50486/tab/6